Is it that hard? Playing Flappy Bird via Reinforcement Learning
Hardik Bansal
You all must have heared about the game famously known as Flappy Bird, that made people so frustrated that the creator of app had to remove the app from the Playstore. It was the hardness and at the same time simplicity of the game that made people go crazy over this game and become a success. Here is one of the funny video that shows how frustrated people become after palying this game. Game that seems so easy to play was one of the hardest one to score. So, do you think it is that hard even for computer? Can we teach computer how to play this game? Let's find out.
Here, I have attached the gif of 10 seconds of game, just in case if you want to get the feel of the game.

If you want to play this game, there are various modified versions (link) available for the same.
Reinforcement Learning
These two words have made too much buzz in last few years, a lot of research in ML have now shifted to actively explore the field of RL. Alpha Go defeated the world's best player in Go using RL, various other platforms like open ai gym have been opened to test the limits of Reinforcement learning, to make computer learn the way we human beings learn things. This is one of the reason why this technology is important in robotics where we need to teach Robots how to do things human way.
So what is this RL based on? To understand it, let us take an example of how we train dogs. When they are young, they don't have any idea about what to do when you say some words or when you do some hand gesture. So what you do is start giving them rewards when they do the desired thing in response of what you say. For e.g., if you keep on feeding dog(act as a reward for dog) when you say "sit" and he sit just after that and not give any reward otherwise, dog will eventually start learning that he has to sit when he hear the word "sit" from you. It will take him some time but eventually he will learn it and save this action in it's memory. This is exactly what happens in reinforcement learning. We give rewards for the things that are desired to us to learn some task and based on that we would like to teach our agent how to maximize the overall rewards at the end of training.
You can read more about RL is in this brief introduction.
Formally, a problem statement for Reinforcement learning consist of a transition function that takes the current state of the problem and current action and gives back the rewards of that action. Our aim in general is to maximize that reward so as to achieve the desired task.
In this blog, we will take a look at one of most famous algorithms in Reinforcement learning called DQN(Deep Q Networks) link, proposed by DeepMind, Google a few years ago.
We will look at this algorithm via game of Flappy Bird. We will develop an AI bot/agent to play the game of FlappyBird using RL especifically using DQN. For now, we will use Tensorflow for neural networks and pygame simulation of Flappy Bird by sourabhv(Github). We will get familiar with different concepts of RL on the go, as we go thourgh the code for it, and believe me once you will be able to understand this code, you can write agent for numerous other games of your own, without much hastle.
Enough of chit chat. Lets get started.
Flappy Bird
This is infinite journey game, where we have to prevent a bird from hitting poles and go through the space between them. One can tap on the screen to give bird a little flap, so that it can gain some height and stay in air for a little bit long. You get a point each time you cross a pole and this is how you increase your score. You are dead if you hit the pole or fall down. Simple Enough? Try it yourself.
So, let us formalize the flappy game.
We have transition function with name frame_step that will take current action and current state as the input and return the new state and reward for that step as the output. Also, we store whether the game has ended or not in done variable. Here, state is an RGB image of size [288, 512, 3]. Action "0" denotes no action and action "1" denotes a single flap. Simulation return a reward of 1 for crossing a pole, -1 at the end of game and 0.1 otherwise after each step for surviving.
Lets get out hand dirty and write some code to see how to use pygame simlation for Flappy Bird game.
import tensorflow as tf
import numpy as np
import sys
import os
# Now, we will import the pygame simulation of the flappy bird game
sys.path.append("game/")
import wrapped_flappy_bird as game
class flappy():
def play():
for i in range(1):
# This is how we initiate one instance of the game
game_state = game.GameState()
total_steps = 0
max_steps = 1000 # Can change this number according to yourself
for j in range(max_steps):
# Here we are just taking a uniform random action
# 0 denotes no action
# 1 denotes flap
temp = random.randint(0,1)
action = np.zeros([2])
action[temp] = 1
new_state, reward, done = game_state.frame_step(action)
total_steps += 1
if done:
break
print("Total Steps ", str(total_steps))
Only after you are familiar with the above code, you should go ahead. It will make things easy to understand and clear as we move foward. It explains from where we are getting the rewards, how we are simulating the environment, how are we feeding our action to the game etc.
So, we know how to simulate the game but the question is how will we make our agent learn how to play the game, how to avoid pipes and score as much as possible? We will use what is known as DQN algorithm (Deep Q Learning), developed by Google's DeepMind team that actually is the basis of AlphaGo.
What are Deep Q Networks?
To learn about DQN networks, first, let us get familiar with the concept of long-term rewards and why they are important?
Long term rewards
To understand the concept of long term rewards, let's look at the game of chess, where we can get reward depending on if we take the pieces of our opponent, and negative rewards if opponent takes our peice. What will be your aim, to take the peices of your opponents as soon as possible, even if it will weaken you position later on in the game or you will try to see if this move will help you make your position strong later on in the game? Definitely the move that will make me win the game, and for that I will have to consider the future and not just look at the immediate rewards. Immediate rewards are deceptive and generally not very helpuful while learning a game. So, what we should aim for is long term rewards rather than long term rewards.
But, how do we define long time words. One simple definition that we are going to adapt is give some fraction of weight to future rewards as compared to immediate reward and then add them up to get total expected rewards. Suppose we have a transition function that tells us reward and next state given current state and current action .
Then, long term reward of step t will be:
and our aim should be to maximize the long term reward at each step and take decision based on that. But again how do we calculate it, for that we need to iterate over all possible future steps which can be quite computational intense and if you will think, it will be nothing more that just a simple brute force to iterate over all possible actions, which is what we are trying to avoid in first place.
Answer for this hidden in the following simplification of above equation.
We define Q value as the maximum long term reward for the action on the state , i.e., , i.e. given current action as and current state as . So,
therefore,
What we can try to do now is try to approximate or you can say learn this function, rather iterating over all the action for all the steps. So, our new aim is to approximate this function called Q that given a state will give long term reward for all the possible action set . Which as we discussed will help our agent decide what action to take.
Things to take care in mind is that we have discrete action space over here, things will be different for continuous action space that we will discuss in next blog.
Next thing we need is a neural network that will approximate this function for us. Also, rather then feeding just a current state(single image of current scenerio) to the network to decide the next action, we will send last 4 greyscaled frames as the input to the network. Providing previous 4 frames will help network better determine the current motion of the bird and take the velocity of bird into account as well.
class network():
def __init__(self, img_width, img_height, name="network"):
self.name = name
self.img_width = img_width
self.img_height = img_height
def net(self):
with tf.variable_scope(self.name) as scope:
self.input_state = tf.placeholder(tf.float32, [None, self.img_width, self.img_height, 4], name="input_state")
o_c1 = general_conv2d(self.input_state, 32, 8, 8, 4, 4, padding="SAME", do_norm=False, name="conv1")
o_c1 = tf.nn.max_pool(o_c1, ksize = [1, 2, 2, 1], strides = [1, 2, 2, 1], padding = "SAME")
o_c2 = general_conv2d(o_c1, 64, 4, 4, 2, 2, padding="SAME", do_norm=False, name="conv2")
o_c3 = general_conv2d(o_c2, 64, 3, 3, 1, 1, padding="SAME", do_norm=False, name="conv3")
shape = o_c3.get_shape().as_list()
o_c3 = tf.reshape(o_c3,[-1, shape[1]*shape[2]*shape[3]])
shape = o_c3.get_shape().as_list()
o_l1 = tf.nn.relu(linear1d(o_c3, shape[1], 512))
self.q_values = linear1d(o_l1, 512, 2)
So, given last 4 frames of the game, the above network will calculate for all possible actions .
Next, we can define the policy we are going to take to make a move in the game. Here, we are going to go with the -greedy policy, where we take random action with probability and follow the actions suggested by above agent otherwise.
def policy(self, algo, sess):
if(algo == "e_greedy"):
temp = random.random()
if temp < self.eps :
temp_action = random.randint(0,1)
else :
temp_q_values = sess.run([self.main_net.q_values],
feed_dict={self.main_net.input_state:np.reshape(curr_state,[-1, self.state_size])})
temp_action = np.argmax(temp_q_values)
return temp_action
Now, we need to look at the loss function that we are gonna use to update our network. we will code what we have written in eqution 2 to update our network. That is
Which can also be written as:
Here, we can calculate the target reward based on current network, as our network(that we defined above) will give us q-values over all possible action space, we can just take maximum over those values and then add the current reward to get target rewards.
def model(self):
# We will se in training function how to calcualte target reward
self.target_reward = tf.placeholder(tf.float32, [None, 1], name="target_reward")
self.action_list = tf.placeholder(tf.int32, [None, 1], name="action_list")
# Remember to calculate self.main_net.q_values, we will also need state
# as required in network class, that we have defined above
observed_reward = tf.reduce_sum(self.main_net.q_values*tf.one_hot(tf.reshape(self.action_list,[-1]),2,
dtype=tf.float32),1,keep_dims=True)
self.loss = tf.reduce_mean(tf.square(observed_reward - self.target_reward))
#Defining the Adam optimizer
optimizer = tf.train.GradientDescentOptimizer(learning_rate=self.lr)
self.loss_opt = optimizer.minimize(self.loss)
# Just printing the names of trainable variables
self.model_vars = tf.trainable_variables()
for var in self.model_vars: print(var.name)
Training
Before defining the training function we need to get familiar with two important concepts introduced in the paper of DQN that made it achieve the accuracy and stability.
Experience Replay : As the training progress, we will store previous state, action, reward lists so that we can teach model from the mistakes we have made in past and not only from the current state we are in. You can see it as if we are testing how our agent have improved upon previous mistakes and if the improvement is not upto mark we will again use gradients to get closer to the desired model. So, to accomplish this, we need to store reward, action and state after every move.
Target Network : This is very important concept that help make network stabilize faster. So, what happens when you update the network on every step, there is a shift in output q-values and because of it the output q-values can get out of control and it becomes hard for the network to become stable. So, to overcome this effect, we use another network that we call target network which we use to caculate the target rewards and we update(by updating target network I mean making it equal to the main network we are using for training) this network after every fixed number of steps only, rather than updating it on every step. This helps in reducing the shift in the q values by the network. So, the loss function now becomes:
where denotes that we are using target network to calculate target rewards.
We will break down the code of training function so that you can relate to various things and concepts I have introduced in the blog.
a. Initiating the network : It consist of two steps:
Defining the two networks. One is main_net on which we will run the Adam optimizer after each step. Second one is target_net that will be used to calculate target rewards during training. We will also equate target_net equal to main_net after every fixed number of steps.
We will define history buffer hist_buffer that will store the experiences(state, action and reward) of last 50000 steps.
def train(self):
# We will use this network to update on every step
self.main_net = network(self.img_width, self.img_height, name="main_net")
# We just introduced the concept of target networks, so we are using two networks
self.target_net = network(self.img_width, self.img_height, name="target_net")
# Initialising the Networks
self.main_net.net()
self.target_net.net()
# Initiaing the model defined above for training
self.model()
# Tensorflow op for initializing the network
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
# Initially making both networks equal
self.copy_network(self.main_net, self.target_net, sess)
# Counter for total networks
total_steps = 0
# This is the experience replay buffer
hist_buffer = []
b. Image preprocessing : In this step we will reset the environment after each episode. One episode consist of one complete game, one game ends when we either reach the terminal state(hit a pole or the floor) or we played the game for 10000 frames. Also, as discussed we feed last 4 frames to the network calculating the q-values, we need to make stack of 4 frames at the start of each game. For first step we will fill starting frame in all the 4 frames. Clearly, it wont make much of a difference as it is just one step, while we will be training for over million steps.
for i in range(self.num_episodes):
# Adding initial 4 frames to the image buffer array
game_state = game.GameState()
# We will use img_batch to feed the 4 images to the q-value network
img_batch = []
total_reward = 0.0
temp_action = random.randint(0,1)
action = np.zeros([2])
action[temp_action] = 1
new_state, reward, done = game_state.frame_step(action)
temp_img = self.pre_process(new_state)
# Storing first frame as the first 4 frames
img_batch = [temp_img]*4
One another function that we have not defined yet is related to pre-processing the image. Since, the original image is an RGB image of size [288 512 3], we will scale it down to [80 80] grey scaled image, so as to reduce the computation for training.
def pre_process(self, img):
x_t = cv2.cvtColor(cv2.resize(img, (80, 80)), cv2.COLOR_BGR2GRAY)
ret, x_t = cv2.threshold(x_t,1,255,cv2.THRESH_BINARY)
return x_t
Sample output for the same can be seen as follow:
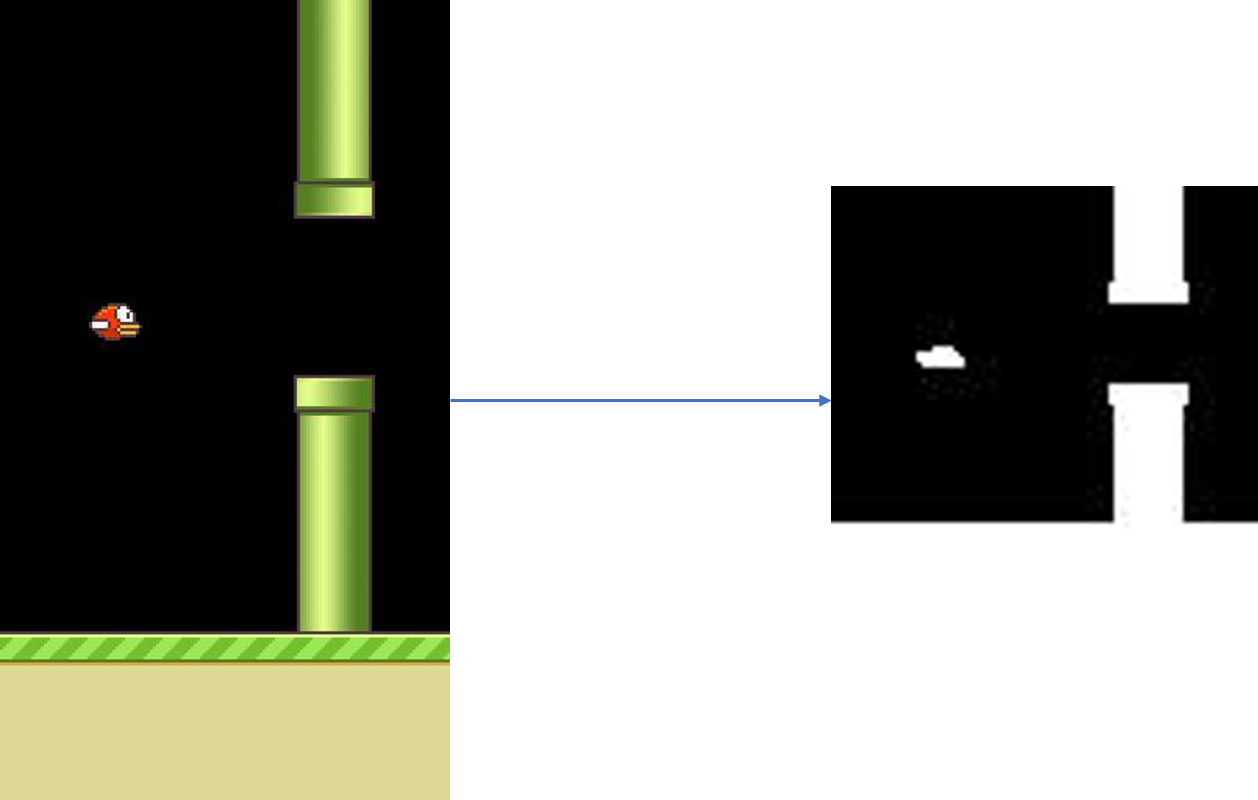
c. Exploration : In this step, we will explore the game for initial training. We will do this this for starting 10000 steps of the game. During the exploration we will only take random action rather than following the -greedy policy.
# Exploration
while(True):
if (total_steps < 10000):
temp_action = random.randint(0,1)
else :
temp_action = self.policy()
action = np.zeros([2])
action[temp_action] = 1
new_state, reward, done = game_state.frame_step(action)
temp_img = self.pre_process(new_state)
new_img_batch = img_batch[1:]
new_img_batch.insert(3,temp_img)
hist_buffer.append((np.stack(img_batch, axis=2), temp_action, reward, np.stack(new_img_batch,axis=2), done))
if(len(hist_buffer) >= 50000):
hist_buffer.pop(0)
img_batch.insert(len(img_batch), temp_img)
img_batch.pop(0)
# Breaking the loop if the state is terminated
if (done):
break
d.) Training : As we discussed in experience replay, we will select random batch from the past experiences and then calculate target rewards for those state-action-reward tuple.
Which we will directly feed into the model that we have already defined above and this is the process that we will keep on repeating.
# Initially, for starting 10000 steps, there will be no training as we will be just exploring the space
if(total_steps > self.pre_train_steps):
# Choose a random batch from past experiences
rand_batch = random.sample(hist_buffer, self.batch_size)
reward_hist = [m[2] for m in rand_batch]
state_hist = [m[0] for m in rand_batch]
action_hist = [m[1] for m in rand_batch]
next_state_hist = [m[3] for m in rand_batch]
# Caculation for target_rewards = r_t + gamma * max Q(s_{t+1},a)
temp_target_q = sess.run(self.target_net.output_weights,
feed_dict={self.target_net.input_state:np.stack(next_state_hist)})
temp_target_q = np.amax(temp_target_q,1)
temp_target_reward = reward_hist + self.gamma*temp_target_q
temp_target_reward = np.reshape(temp_target_reward, [self.batch_size, 1])
# Call the Adam optimizer for the training of main_net
_ = sess.run(self.loss_opt,
feed_dict={self.main_net.input_state:np.stack(state_hist),
self.target_reward:temp_target_reward,
self.action_list:np.reshape(np.stack(action_hist),[self.batch_size, 1])})
# Here we are updating the code to update target network
# look at the final code on github for the code of copy_network function
if(total_steps%self.update_freq == 0):
self.copy_network(self.main_net, self.target_net, sess)
total_steps+=1
Thats it. Once it is done, one can load the checkpointed model to test the model.
Congrats. You can now score as much as you want in Flappy Bird.
Results
After training for 2 million steps, I was able to get the model that can play flappy bird for as long as you want it to. So, it will keep on playing for very long. I have uploaded the complete code and the trained model on the github repo.
Further Improvements and Directions
There are other way we can train this game. While the input over here was an image, we sometime also have acces to direct properties like distance from next pole, current velocity in x-direction etc. You can look at this link for more details.
We can also look in details for deeper neural network to learn q-values.
I was not able to explore how long will it take to train for larger learning rate values, but one can explore the effect of increasing the lr values for the same.
We can also use the action-critic model algorithm, namely, ddpg which is based on policy gradient approach to deal with this problem. We can then compare the training time and performance for the same.
Training time is too long for a cpu only machine so can't be trained easily. Apart from that pygame is further making it slow. So, one can try to use open ai gym version of Flappy Bird for this, whose rules are only little bit different.
Credits: I would like to thank to yenchenlin, as my implementation of flappy bird is inspired from his repo.